Le XML (extensible mark up langage) est le langage avec lequel sont encodés les inventaires d'archives, selon un schéma spécifique (et international), l'EAD (pour encoded archival description).
Le XML ead permet de décrire tous types d'inventaires d'archives tout en respectant des fondamentaux de l'archivistique :
- respect de l'organisation hiérarchique .
- non répétition à tous les niveaux dune information commune (le niveau inférieur hérite par exemple de l'indexation ou de l'intitulé du ou des niveaux supérieurs).
C'est relativement invisible pour les usagers lambda et archivistiquement assez pertinent. Les cotes sont encapsulées dans des balises "cote" (unitid), de même pour les dates, normalisées (unitdate), l'intitulé (unittitle), ou encore les indexations (controlaccess)...

Nouveauté des derniers mois : on peut désormais librement télécharger des inventaires en xml en France ! Il fallait auparavant, pour avoir "légalement" des XML francophones, aller faire se réfugier auprès des archives de Genève. L'ouverture du portail France Archives comble cette lacune. L'accès aux fichiers encodés en XML ead permet aux chercheurs et réutilisateurs de toute sorte d'avoir des données structurées un peu plus utilisables qu'un export PDF... (cf tutoriel sur Open Refine pour transformer un xml en csv). Vivement que les portails documentaires se dotent par ailleurs d'une icône de téléchargement direct en xml aux côtés de l'icône PDF...
Bref, le xml c'est assez chouette (#jaimelecode) mais il faut tout de même dire que les inventaires sont très loin d'être tous convertis et en ligne, et que parfois ce n'est pas la panacée, notamment pour des recherches plus ou moins complexes dans l'arborescence de gros inventaires ...
Pour aller plus loin...
- Wikipédia, XML et Description archivistique encodée
- France Archives, article sur l'EAD
- BNF, rubrique sur l'EAD
- Enssib, Faire un inventaire simple en XML EAD
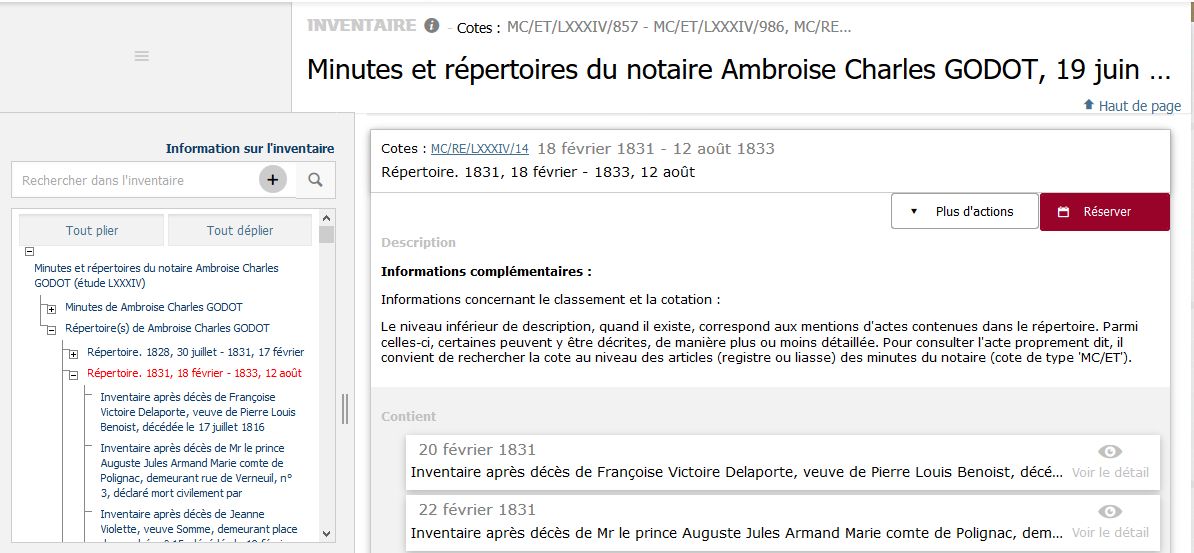
- Archives nationales, Minutes et répertoire du notaire Ambroise Charles Godot

Comments